2019年度国家自然基金医学科学部共批资助10138项目,批助金额总计441310万元。这些项目中大部分都与编码基因有直接或间接的关联。其中,与通路(pathway)关联的有1349项,金额4.89亿;与miRNA相关的有630项,金额2.3亿;与lncRNA相关的有395项,金额1.45亿,与甲基化相关的有213项,金额8748万,与突变相关的有190项,金额7410万;
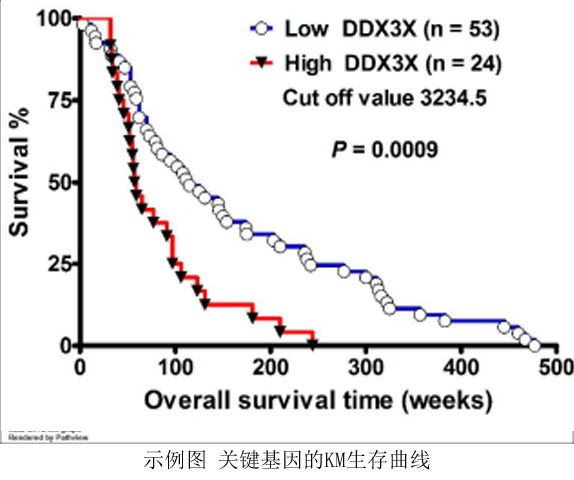
如何获得有创新意义的疾病靶标基因(mRNA,Protein,lncRNA,circRNA,miRNA,Mutation等)是项目申请及文章写作时最常见的问题。
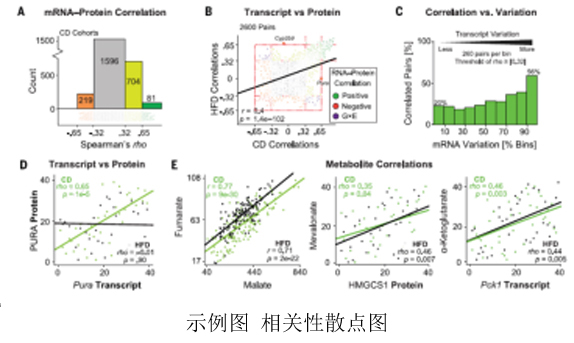
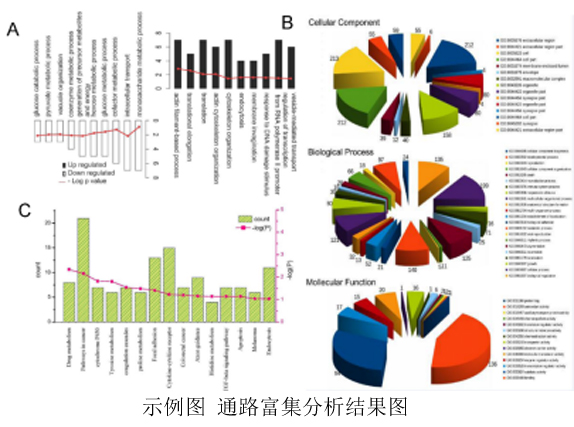
目前,多组学整合分析是一个非常热门且创新的方向。通过多组学整合分析我们可以更加快速、准确的找到与研究方向关联的biomarks。它的核心原理是期望通过高通量数据,找到所有基因在不同组学水平中的变化并进行分析,获得关键基因在各个组学都有显著作用。
多组学整合分析的原始数据来源有两种:(1)自己采集样本做高通量测序/芯片/质谱等;(2)使用公共数据库中的组学数据(比如TCGA、GEO、EBI、SRA、CGGA、PRIDE等)。
那么我们即便有了非常好的数据,又该怎么办呢?
用什么方法,什么工具?可以获得哪些结果,生成哪些图片呢?
基于这个目的,我们开展了该培训班。通过三天的学习,我们了解多组学整合分析思路对项目及文章的帮助,以及实操常见的数据库、在线工具和本地软件。使得学员可以自己完成一个完整的分析报告并获得疾病相关的靶标基因。